
目的
- TROCCOでマネフォ連携が来てたので軽く触ってみましたのメモ記事です
- 具体的にはクラウド会計(Plusではなく)の方で、中小の企業様でもよく使われているほうです、弊社も愛用させて頂いております
機能の確認
- コネクタとして存在を確認できました、その他freeeやPlusなども増えていますね
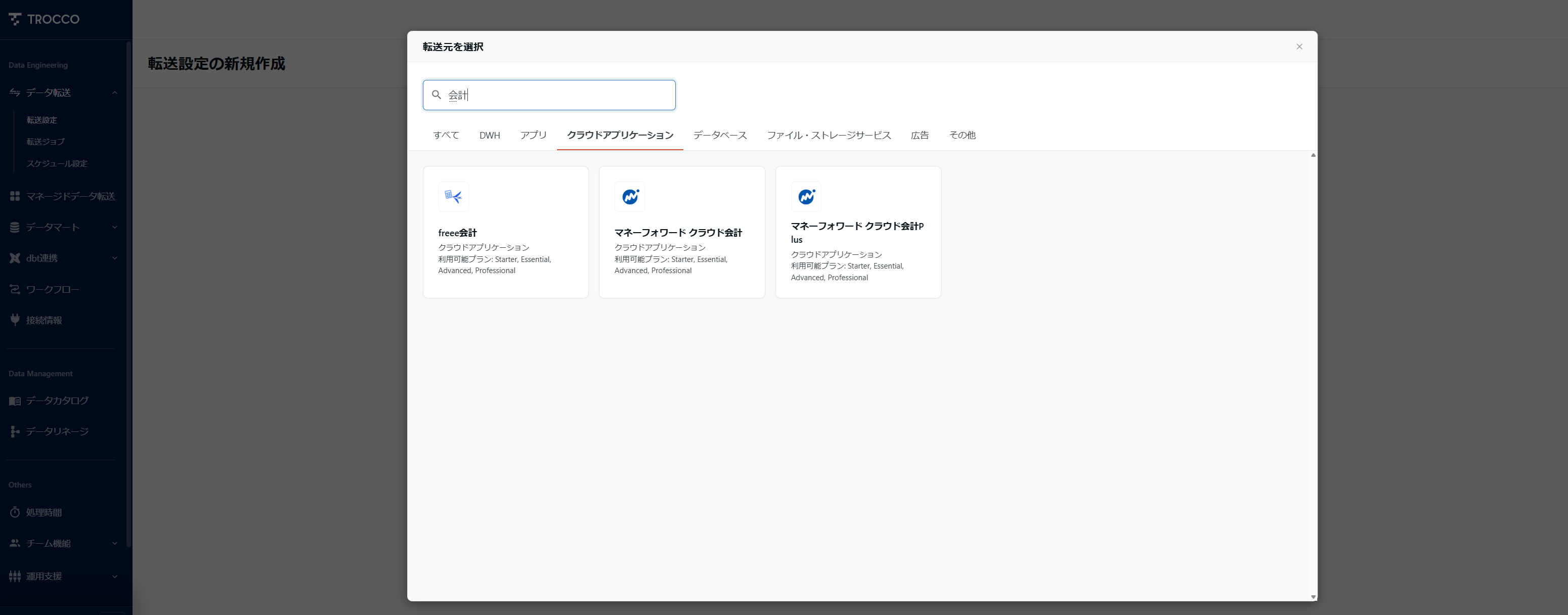
取得できる情報は以下という感じ。
事業者情報一覧
仕訳一覧
残高試算表の貸借対照表
残高試算表の損益計算書
勘定科目一覧
部門一覧
税区分一覧
補助科目一覧
取引先一覧
使われる可能性が高いものとしては下記なイメージでしょうか。
残高試算表の貸借対照表
残高試算表の損益計算書
仕訳一覧
貸借対照表や損益計算書はどのような使われ方をするか次第ですが、月単位以上の更新頻度で見られることが多いと思います。
マネフォの運用に合わせて、データを取得頻度を合わせて設定する必要があります。
メインは仕訳一覧になります。こちらもちゃんとした仕訳の頻度にもよりますが、
日常的にマネフォの関連サービスや外部サービスからデータが集まってくるので、ミニマム日単位で追うこともできそうです。
例えば、月末で締めて翌月で処理を回すという形であれば、下記のように前月の1日から仕訳を取得するイメージでしょうか。
月中で回すと既に締めたものを取り直すことにもなるので、データの積み上げには Delete/Insert が必要になります。
- BigQueryに転送してみた結果は下記です。
- 金額や取引先が記載されているカラムの黒塗りが大きくて、あまり内容の無い画像です...
- 弊社は2023年11月創業なので、2024年の初頭は取引やお金の動きがほぼないため、レコードの数が少なかったです。一般の企業さんでは大量のレコードが取得できると思います。
上記黒塗りで記載したカラムには下記のようなデータが入ってました。
(内容はダミーにしてますが、売掛金:100万円のレコードのイメージです)
[{"remark":"振込 [企業名]","creditor":{"trade_partner_code":null,"department_name":null,"account_id":"m2SAMlflyEMFDn","department_id":null,"tax_value":0,"account_name":"売掛金","sub_account_id":null,"value":1100000,"invoice_kind":"INVOICE_KIND_NOT_TARGET","sub_account_name":null,"trade_partner_name":null,"tax_id":"CuEafV2ueQcd","tax_long_name":"対象外","tax_name":"対象外"},"debitor":{"trade_partner_code":null,"department_name":null,"account_id":"QXynRBVlpFZGDs7HPaQ","department_id":null,"tax_value":0,"account_name":"普通預金","sub_account_id":"h8agLHqHuF2%2BisCTi","value":1100000,"invoice_kind":"INVOICE_KIND_NOT_TARGET","sub_account_name":"Rounda法人_[○○銀行]普通預金(有利息)","trade_partner_name":null,"tax_id":"CuEafV2ueQcdUUI","tax_long_name":"対象外","tax_name":"対象外"}}]
上記のリスト・Json形式のデータをSQLで整形して再格納することが必要です。
ただし、既に仕訳の中でも取得したい内容が固まっているなら、TROCCOの転送時点でTEXTをパースして格納することも可能です。
以降はほぼ黒塗りの結果しか出せないので略としますが、ダッシュボード上の可視化などにも簡単に繋げられます!
利用ユースケースとLLMとのすみ分け
財務データを手軽に取得できるというのは大きな利点です。
合わせて、非財務(SFAやMAなど)からもデータが引き込めるので、具体のビジネスKPIと金額を照らし合わせて分析できるのは大きな利点となります。
TROCCO + データウェアハウスを利用すれば、国内外の多種なコネクタで拡張性のある基盤を実現することができます。
ただ「深く分析をする」という点においては、LLMを用いた分析も手軽になってきています。
特に現在のMCPの過熱化の如く、LLMに合わせたプロトコルやデータの取得方法もさらに発展していくでしょう。
(例えば、マネーフォワード側でもMCPサーバーが提供されるとか...)
ですが弊社としては、もしLLMのプロトコルを通して、データ取得や加工を意識せずに分析までできるようになったとしても
データ基盤を整えること自体が不要になる、とは考えていません。
具体的にはLLMで扱えるコンテキスト・Tokenの問題、Toolの選択・選択肢自体の増加の問題、そもそものLLMの精度(認識)の問題など挙げられます。
例え、それらの問題が時間(モデルの発展)とお金(コストカット)で解決されていくとしても、
整形された自社データを適切に保持し、活用できてている企業は、どんな新しい技術が来ても対応が取れるはずです。やはり、選択肢が多い企業が強いです。
LLMによって、ステップを飛ばして分析まで繋げられるケースも出てきている状況ではありますが
自社のこれまでの取り組みと、これからの取り組みに合わせて、適切な導入ステップを設定することが重要だと考えています。
データ量やユースケースに合わせて、適切にプロセスを設計を行っていきましょう!
宣伝
弊社ではデータ基盤策定からLLMまで、お客様にあったプロセスでの提案とご支援が可能です、お気軽にお問合せください。
また、中途採用やインターンの応募もお待ちしています!


