
はじめに
前々回と前回で一応話の流れがあるので、よろしければ下記も目を通していただければ、より背景を掴んで頂けると思います。
あと TROCCOのアドベントカレンダー15日目 も兼ねております。
DWHに取り込んだデータをLookerStusioで可視化する
今日の本題ではないので、さらっと触れます。
データ連携
元々Excel管理から始まったこのお題ですが、DWHに蓄積することによって可視化がサクッとできることは大きなメリットです。
特にExcelではグラフは作れても、かなり限られたグラフを単体で作ることしかできません。(アドオン等使用すればまた別の話にはなりますが)
DWHにデータを配置することによって、複数の BI(ビジネスインテリジェンス) ツールを簡易に利用することが可能となります。
BIツールとして代表的なものとしてはTableauやPowerBIがあり、自社での利用方針(MIcrosoftがメインワークスペース、外資サービスも含めて積極的に利用するなど)もあるかと思いますが
意図しないBIサービス乗り換えが後に発生しないように、しっかりとしたサービス選定を行うことは重要です。
話が脱線しましたが、前回Google BigQueryを使用した経緯もあるので、一番BigQueryと親和性も高くライトに使えるLooker Stusioを使用してみます。
ちなみにBIgQueryでは今年から、カラム名に日本語(マルチバイト文字)が使えるようになっています。
特に業務から直通するデータのカラム名や、専門業のデータの場合だとカラム名の論物変換における工数は地味に面倒な観点であり
別途定義資料やdescriptionを読み込まずとも、カラム名で判断できるというのは素晴らしいことだと思います。
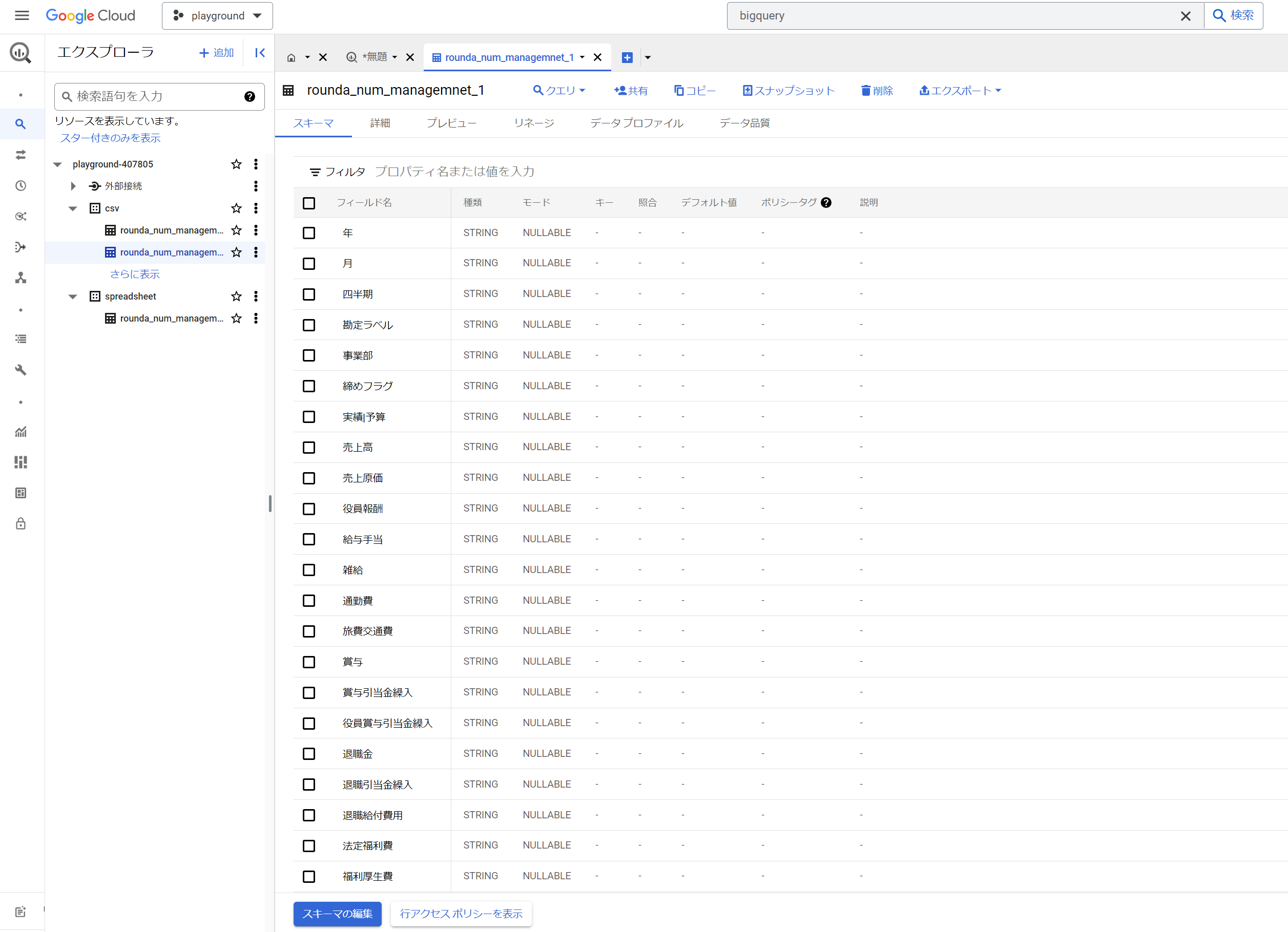
ただし、2023年12月時点でもLookerstusioでは日本語カラムの利用は許可されていません。(知らずにデータ連携するとエラーになります)
なので、Lookerstusioで描画することを目的している場合は、大人しくカラム名に英数字を利用するべきです。
または、Lookerstudio上からデータ参照する際のカスタムクエリで、AS句に無理やり英数字変換を施すことも可能ですが
行き当たりばったりの対応が否めないので、避けるべきでしょう。
可視化作業
LookerStudio上での作業は、公式のDocや他のBlog等でもたくさん取り上げられているので割愛します。
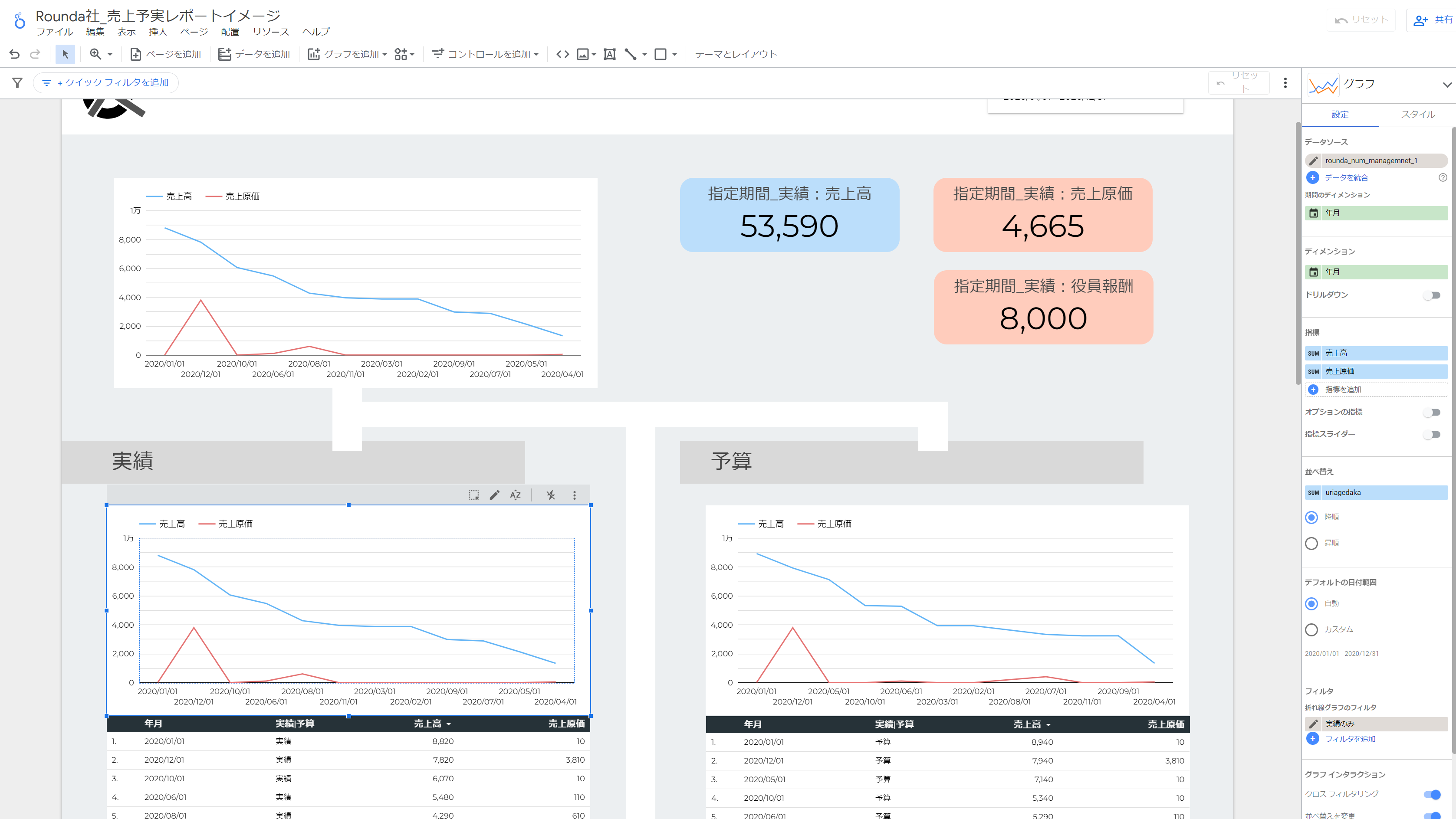
もし今回の事業データをまず概要から徐々に可視化していくなら、数十分程度で下記のようなイメージを作成できます。
もちろん、ビジュアルや導線にこだわりだせば、さらに素晴らしいものが爆誕していくでしょう。
ただし、この点は良い点でもあり、悪い点でもあるのですが、LookerStudio上での数値表現とアクションには一定限界があります。
そのため、LookerStudioを利用するモチベーション一つとしては
「パワポの延長線ぐらいの気持ちでサクッと可視化したい」
という部分に尽きると個人的には思っています。さらに発展的な機能拡張への期待と、有償Lookerへのアセスメントに繋げていく形ですね。
ここからが本題、DWHをより柔軟に使いこなす
データ連携はできるけど、ちょっとした不満ありな状態
前回の記事に記載した通り、Excelをインタフェースとして、数値の変更はExcel上で行い
TROCCOのようなサービスで、簡易にデータを一括転送する方法は分かりやすいし、導入もしやすいです。
ただ、ちょっとした変更を加えた場合でも
Excelを修正して、関連の取り込み用ジョブを起動して、反映まで少し待つ
という動作が入ります。特に一度修正後に、再度誤りに気づきまた直すシーンもざらにあり
その都度、先の工程をやり直すというのは地味に面倒なものです。
なので、少しユースケース深堀と状況をまとめてみます。
・本当にちょっとした内容をDWH上に反映し、ダッシュボードに連動できればよい
・特に事業系の数値などは何度も設定しなおすことがザラにあるので、反映までの工程がなるべく少なく短くあってほしい
・事業や会社の全体数値(サマリ)は複数人で編集するかもしれないが、個々の事業部等は基本管掌役のみの編集(同時編集の考慮は不要)
ここから考えられるのが、直接DWHに向けたアプリケーション活用という観点です。
Streamlit
アプリケーションと聞くと、複数のクラウドサービスを利用したり、フロントやサーバーサイド、DBなど色々検討・構築することがあり
一般的な観点からみると「片手間でやれるものではない。さらに、オレオレな感じで適当に組むと、一瞬で属人化しそう」という印象ではないでしょうか。
その点、昨今だとフルマネージドなサービスも多く、基本はコードをデプロイするのみでホスティングできるサービスなども多くありますが
またそれらを調べたり、「利用する人数も限られているのに、そこまで考慮する必要もあるか?」という感じにも正直なります。
その一つの解決案であるのが、Streamlit という形になります。利用するメリットとしては
- 現在の分析作業や可視化の延長線上で作業できる
- さらに新たな言語や環境は不要で、Python上でやれることを増やした
- そのやれることの代表的なものが、簡易的なアプリケーション構築である
ExcelからPythonに技術が飛んでいるので、Excelだけ利用したい or GUI上での操作に注力したいという方には、少しハードルがあります。
それでも、ちょっとしたアプリケーション作ろうのハードルをグーンと下げたことには間違いないので
是非、触ってみてほしいという印象です。
DWHに取り込んだデータをstreamlit上で可視化・編集する
開発の流れ
開発の流れは非常にシンプルで下記
- ローカル環境でPyhtonコーデイング(例えば、demo.pyという1ファイルにコーディング)
- ローカルでデモ起動(
streamlit run demo.pyとコマンドを打つ) - 問題なければ、Streamlit Community CloudにDeploy
何なら pyファイル を一つ作れば、その時点で使えるものができてしまうという形です。
認証認可
ライトなアプリケーション故に、小難しいことはできません。
従い、何も考えずにDWHに存在するデータを参照するようなコードを書いてデプロイをしてしまうと
誰にでもデータが見えてしまう、完全に利用NGなアプリケーションが誕生してしまいます。
(もちろんcloudへのデプロイ時にprivate or publicの選択はあるので、その部分でハードな制御はできます)
では認証のフローもアプリケーションに組み込んでみましょう。
既にGoogle Cloudを利用しているので、Google OAuth2.0のクライアントを使ってみましょう。
といいつつ、既に実装されている方がいらっしゃったので、大いに参考にさせていただきました。
上記から認証や環境周りで変更した点としては
シークレット情報の扱いを環境変数から st.secretsへ
後続でcloudへのdeployもあるので、secretsの利用に書き換えました。.streamlit/secrets.tomlを配置して、ローカルではこちらを参照するようにしました。
#旧設定
#client_id = os.environ["GOOGLE_CLIENT_ID"]
#client_secret = os.environ["GOOGLE_CLIENT_SECRET"]
#redirect_uri = os.environ["REDIRECT_URI"]
#新設定
client_id = st.secrets["GOOGLE_CLIENT_ID"]
client_secret = st.secrets["GOOGLE_CLIENT_SECRET"]
redirect_uri = st.secrets["REDIRECT_URI"]
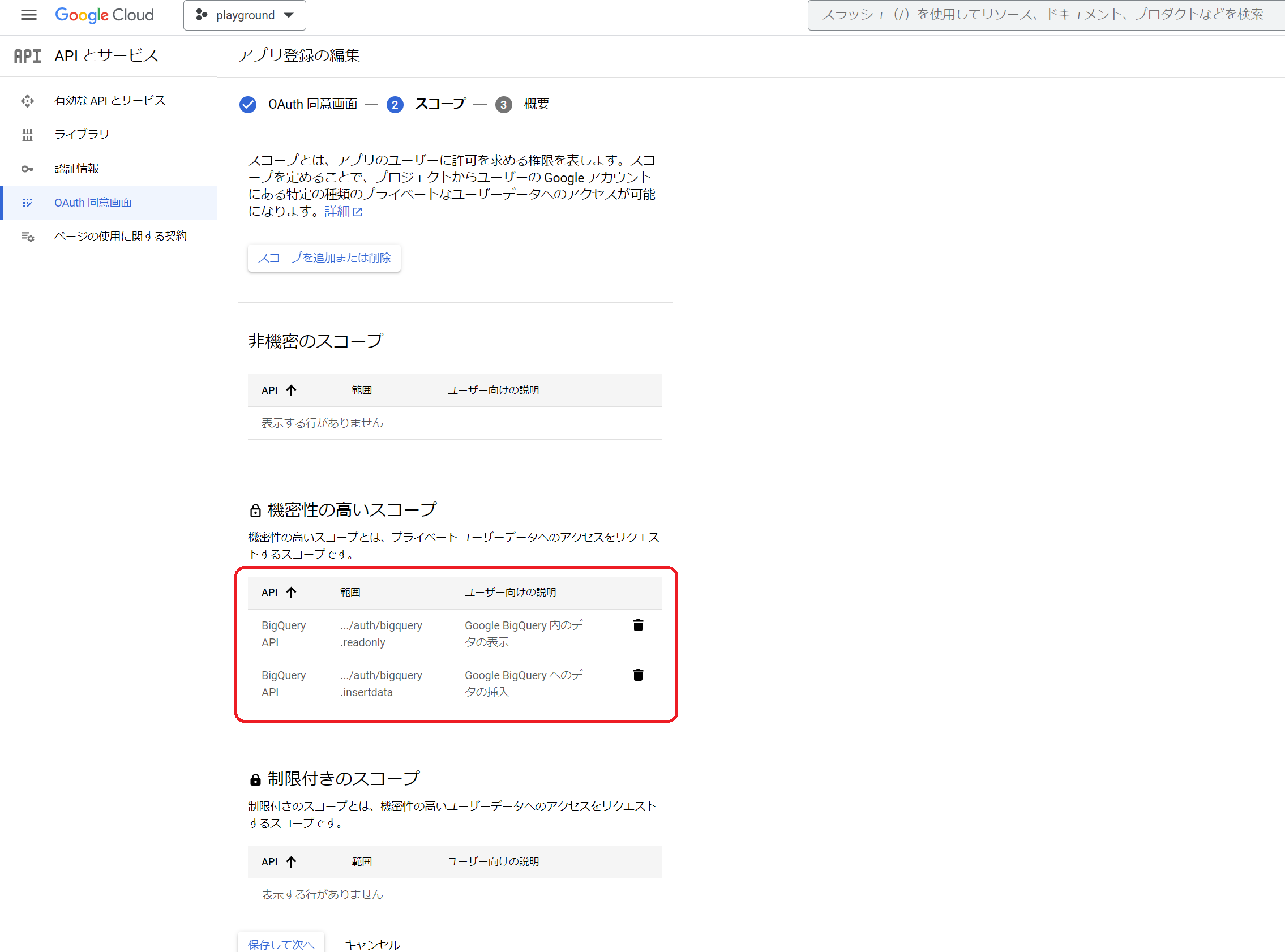
OAuthのスコープにBigQuery権限も含める
BigQuery側のデータを表示したり、編集することが目的なので
その対象スコープを含める設定を入れます。(赤枠の部分)
あとはPythonコード側のBQスコープを修正したり、こまごまとした部分を修正していますので
それらについては下記のsampleコードをよろしければご確認ください。
ローカルで実行の上で、クラウドへデプロイ
ローカルで実行するとこのような形までたどり着けます。
ちなみにBigQueryのカラム名には日本語を使ってますが、こういう場合だと非常に利用しやすいですね。
内容が長くなってきたので割愛しますが、
Streamlit Community Cloudへのdeploy自体も簡単で、github上にレポジトリを作成し、下記画面の内容を転載するだけです。
その際に、事前に取得した各secretsの情報をGUI上から設定することを忘れずに。
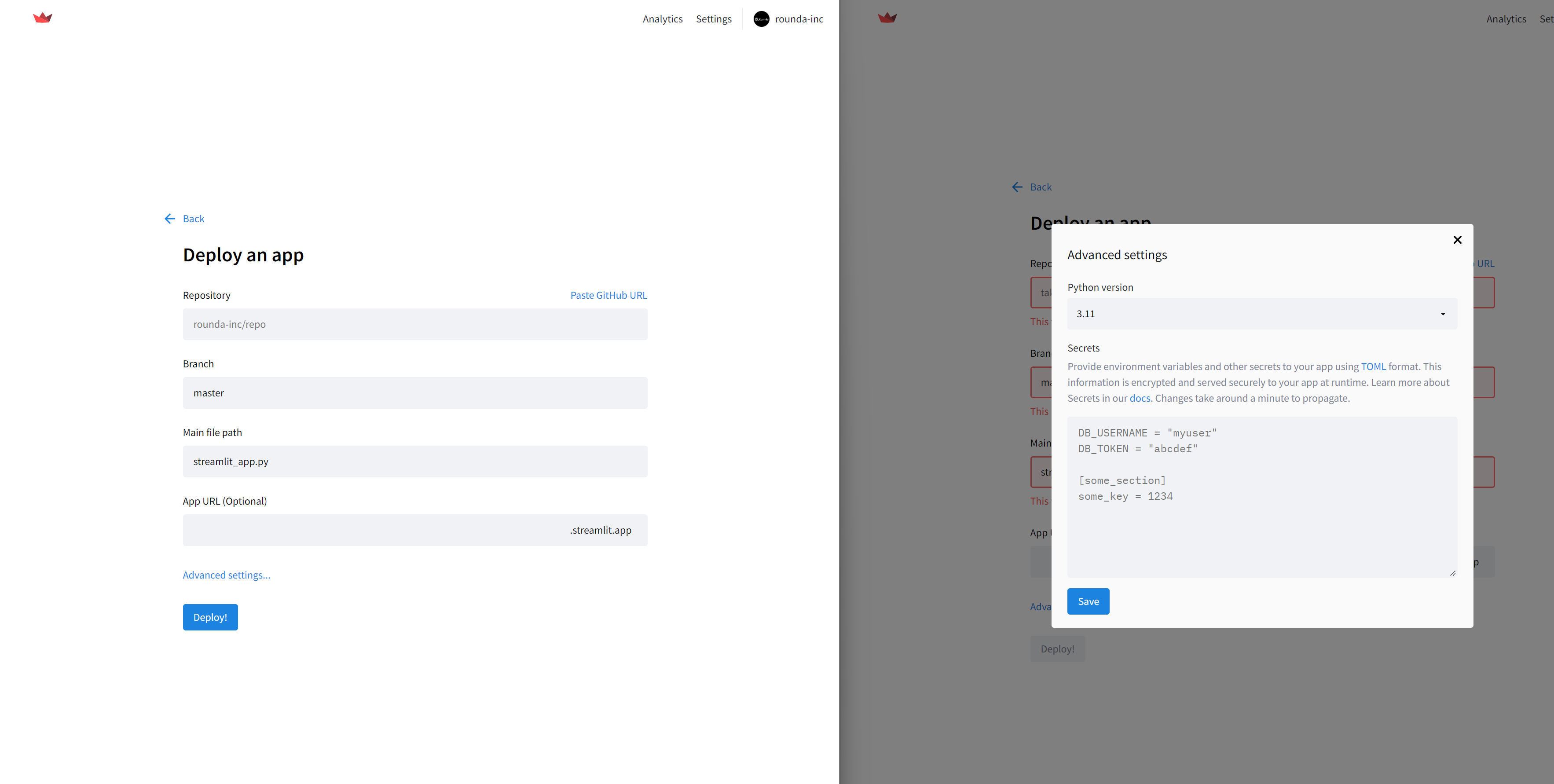
デプロイが完了すれば、Google OAuth側のリダイレクト設定にも取得できたURLを加えておきましょう!
これで実際に公開された(あくまで内向きですが)アプリケーションを利用することができます。
さらにStreamlitで実現できる点を書き出したら、なかなか終えられないので一旦ここでとどめます。
が、上記動画とsampleコードからも分かる通り、アプリケーションの見栄えは別のライブラリで整えたり、st標準のグラフを追加しつつ
BigQueryへのデータ参照操作は完全にPythonクライアントを使ったコードを記載するだけです。
ページ遷移がない分、画面遷移やハンドリングは少し戸惑うかもしれませんが、必要十分な機能がそろっています。
編集済みのデータをTROCCOにて転送する
前回の記事では、
Excelで編集 => TROCCOで転送 => DWHに格納
という形でしたが、
StreamlitでDWHを直接編集 => TROCCOで転送
ということが可能となります。ではどこに転送するのか?
こちらは各サービス(例えばセールスフォース)やDBが想定できると思います。
DWH上で直接最新化(または手直し)されたデータを集計し、最終版のデータを転送する。
このフローを扱う人数が多ければ別途問題が発生しそうですが、DWH自体の機能拡張が進む昨今だと
そのような構成も現実的に使そうだと考えています。
TROCCOのAPI機能
TROCCOはAPI機能を持っており、転送ジョブやワークフローの個別起動や
各ジョブのステータス状況チェック(ジョブが正常終了したか確認)を行うことができます。
POSTするだけなので、Streamlit上でデータの編集が完了したら
ボタンポチでデータを転送することもできます。例としては、troccoを使って先のBigQueryデータをBOXに転送するジョブを作成し
そのジョブをAPI経由で呼べるボタンを置いておきました。
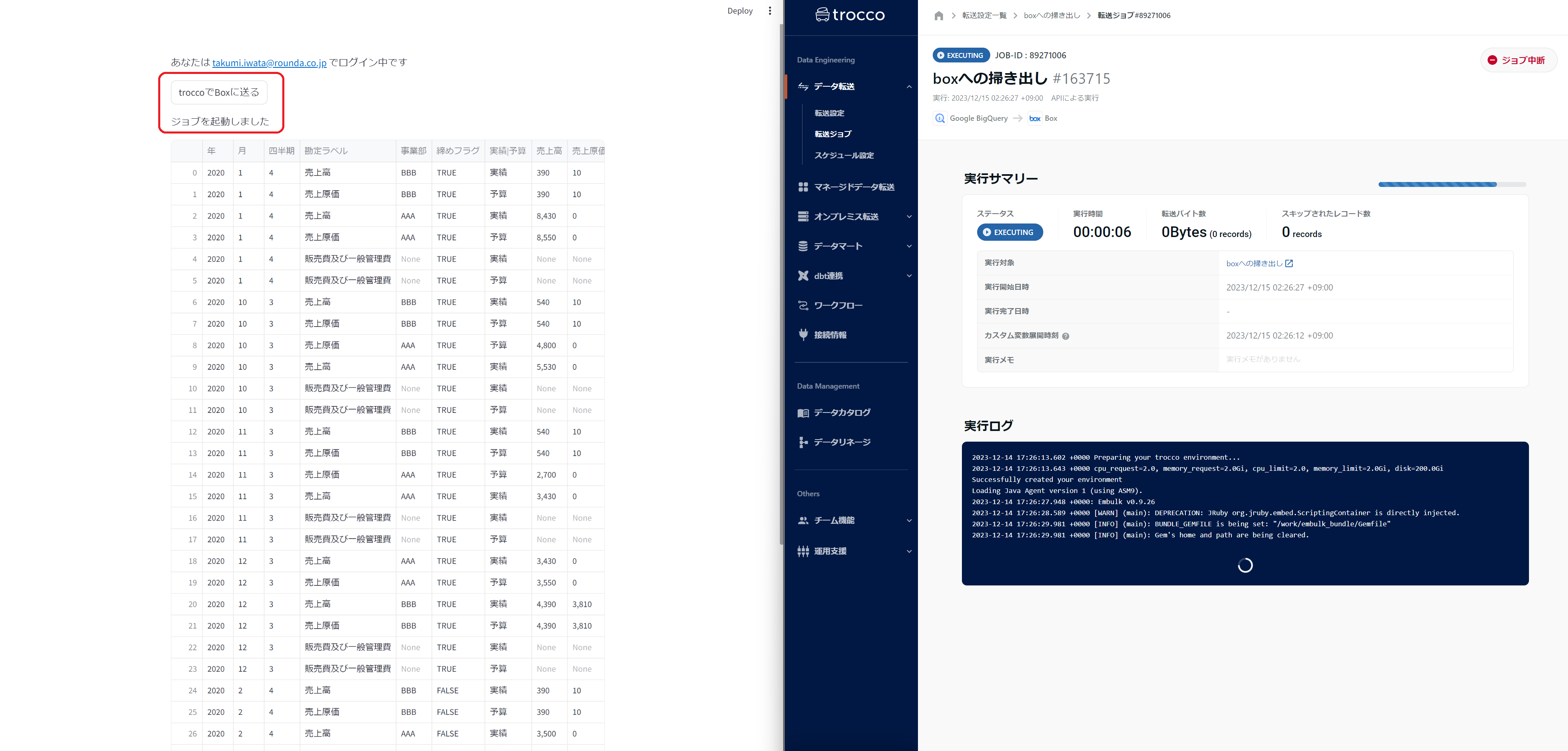
if st.button('troccoでBoxに送る'):
url = 'https://trocco.io/api/jobs?job_definition_id={troccoID}'
headers = {
'Authorization':'Token {troccoのアクセストークン}'
}
requests.post(url, headers=headers)
st.write('ジョブを起動しました')
フォーマットがあまり変わらないデータ連携などは、アプリ側に集約してしまうのもありですね。
まとめ
Excelから始まった全3回分の記事ですが、結論です。
- Excelはやはり万能であり、可視化やコアな分析が不要であれば、必要十分ではある
- DWHとExcelと併用して運用することで、集約でき手軽にBIに着手できるのは強み
- Streamlitは簡易なアプリケーション構築に希望が持てる良いツールであり、利用シーンをブレイクダウンできれば、十分上記にとって代われる
- troccoはどのシーンでも何かしらに使えて、相変わらず便利
利用するサービスが分散することは恐れるべきですが
サービス検証を止めてしまうことはさらに恐れることなので、引き続き最適な方法を検討できればと思います。
宣伝
弊社ではデータ基盤策定からLLMまで、お客様にあったプロセスでの提案とご支援が可能です、お気軽にお問合せください。
また、中途採用やインターンの応募もお待ちしています!


