モチベーション
- しっかりした内容ではないのでメモベースの記事です
LLMの下処理と管理のポイント(概要)
- inputとなるファイル形式が構造、非構造、半構造など多岐にわたる
- 画像の場合はOCR、音声の場合は文字おこしなど、以前だったらML側で1テーマになっていたレベルが前処理(マルチモーダル化)
- 読み取れた情報(メタ情報含む)は対象のオブジェクトとの紐づけと持ち方が結構重要
- PDF内の画像であれば、ページ数、前後の文脈
- 音声であれば、その発話タイミング(時間)など
- 上記に加えてLLMを用いる(RAGをやりたいなど)場合は、何らかの自然言語とベクトル情報(embedding)をセットで持つ必要がある
- LLMの作業が業務として周りブラウザ上での作業やアプリケーション的な動きが必要な場合は、RDBMSやベクトルDB, ストレージなど適材適所な管理がよさそう
- オブジェクト管理、RAG利用、検索に特化している場合などは、既存のアプリケーションに対して検索エンジン(vespaなど)をかますのがよさそう
- LLMの結果をアプリケーション側ではなく分析用途で使う場合は、BigQueryやSnowflakeに丸っと全部入れておくのもあり
- そういう点ではembeddingの結果をベクトルDBと一般的なDWHにおくメリデメは整理したほうがよさそうなイメージ
- FeatureStore的な位置づけが強いシーンとは?
今回の検証
- まず下処理として、PDFの画像や図の読み込みを試してみる
- UnstructuredやPyMuPDFなどサービスを使う
簡単に紹介
Unstructured
- 結構なファイル形式(拡張子)に対応しており、非構造 => 構造化してくれる精度も良さそう
- ただ実態としてはラッパーとして全部乗せ感もあり、今後さらにモジュールとして膨らんだりもするのかな~という印象
- 今回はOSS版を使用するが、サーバレスのAPIも提供している。公式Docの文言としてはOSS版は運用目的では設計されておらず、機能も課金に対して劣るとのこと。今後APIを使うシーンはありそうな気もする。
PyMuPDF
- こっちは歴史も長く、古き良きという印象
- Unstructuredと比べての汎用性は落ちるが、PDF以外にも対応
- イメージも含まれるが、古典的な方法と新しい技術をうまく組み合わせているのかな~という印象
- 最終的に取得したいデータが参照できないときに、力業や固定でチューニングできるのはこっちのイメージ
他にもいくつか候補はありそうですが、汎用性と使い勝手を事前に調べた感じだとこの2つかなと。
画像の読み取り
対象のPDFオブジェクト
- PDFとして下記のシマノさんが公開していたオンラインマニュアルを参照(そろそろディスクブレーキのロードバイクが欲しい)
- 画像に加えて絵や図も含まれており、これぞあるあるのマニュアルかなと
Unstructuredで実行
- 環境はDocker上に用意
- quickstart docker
- 蛇足だが、OSは
Wolfiはパッケージはapk管理なので注意
- コードは下記でとてもシンプル
from unstructured.partition.pdf import partition_pdf
import time
filename="shimano/DM-MBBR001-04-JPN.pdf"
# start time
st_tm:float = time.time()
# start load & analysis
elements = partition_pdf(filename=filename,
strategy='hi_res',
extract_images_in_pdf=True,
extract_image_block_types=["Image","Table"],
extract_image_block_to_payload=False,
extract_image_block_output_dir="./images"
)
# end time
ed_tm:float = time.time()
print(f"{ed_tm - st_tm}[sec]")
PyMuPDFで実行
pip install PyMuPDFでOK、やっぱり軽い
import fitz, time
filename="shimano/DM-MBBR001-04-JPN.pdf"
# start time
st_tm:float = time.time()
pdf_file = fitz.open(filename)
num_of_pics = 0
num_of_pix = 0
for page in pdf_file:
images = page.get_images()
# 一応各ページのスクショも取ってみる
pixmap = page.get_pixmap()
if pixmap:
num_of_pix += 1
pixmap.save("./pymu_images/extracted_pixelmap{}.png".format(num_of_pix))
if not len(images) == 0:
for image in images:
num_of_pics += 1
xref = image[0]
img = pdf_file.extract_image(xref)
with open("./pymu_images/extracted_image{}.png".format(num_of_pics), "wb") as f:
f.write(img["image"])
pdf_file.close()
# end time
ed_tm:float = time.time()
print(f"{ed_tm - st_tm}[sec]")
結果
処理速度
- 全45ページのPDFを読み取り、png出力するまで
- PyMuPDFのほうが断然速い
Unstructured | PyMuPDF |
|---|---|
398.43秒 | 1.68秒 |
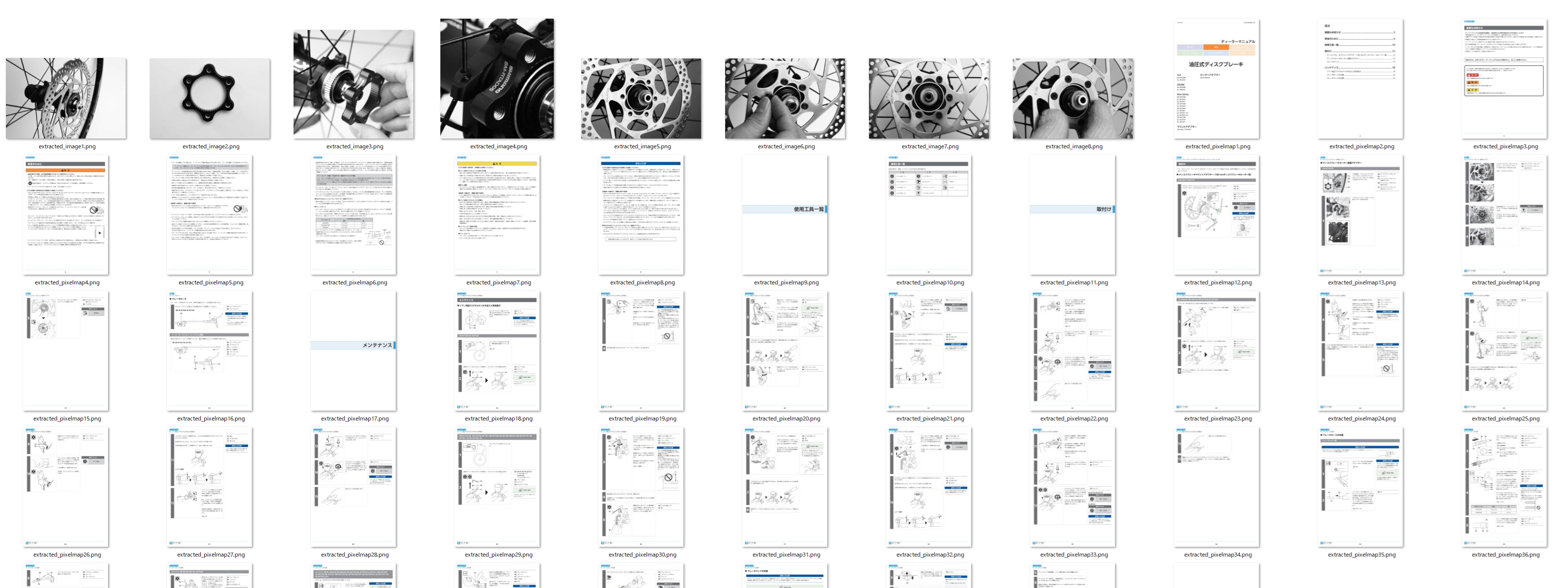
抽出画像
Unstructured
- 画像・図も含めて大体が取れている(表は未検証)
- 一部切れている画像なども見受けられるが、十分対応はできそう
- 画像のメタ情報も取れるので、ページや配置から文章と紐づけを行う必要あり

PyMuPDF
- 画像は取れているが、図や絵が取れていない(おそらく取り方はありそうだが)
- ページのスクショは簡単に取れる
結論と考察
- 処理速度は PyMuPDF が高速で大量のPDFをパースする場合などにも使いやすい印象
- 簡単なコードで余すことなく、画像や図を拾う場合だと Unstructured
- ただ実際にこのPDFをINPUTにRAGで回答するサービスなどを検討した場合、どれだけピンポイントで情報をみたいかにゆだねられる印象
- 結局はマニュアルの前後の文脈が必要なシーンも多い
- 本文をほぼ完璧に読み取り、ほぼそれで回答できている場合などは Unstructured のようにピンポイントで画像を出すのがよさそう
- 精度があまり高くなく、あくまで候補として出すという形であれば、補足としてページスクショをそのまま、または画像の座標をもう少し狭めて出す場合の方がよさそう
- 今回やらなかったが、OCR(Text)の観点を見ると、その点は PyMuPDF が優秀な印象であり、もしかしたら組わせるのも...とか考えられが魔改造にもなりそう
さいごに
- LLMの登場により下処理の対象が増えたことと、管理対象も増えたので考えることはより増えた印象です
- Roundaでは引き続き、データ基盤やLLMまわりなど広く取り上げていきます。
宣伝
弊社ではデータ基盤策定からLLMまで、お客様にあったプロセスでの提案とご支援が可能です、お気軽にお問合せください。
また、中途採用やインターンの応募もお待ちしています!