1. はじめに
2022年11月以降、ChatGPTに代表される大規模言語モデル(LLM: Large Language Model)は非常に早いスピードで性能が改善されており、ユーザーの質問に対する回答能力は人間を超えるレベルまでに到達しています。
引用元:ChatGPTとは?できることや活用事例などをわかりやすく解説
https://www.nec-solutioninnovators.co.jp/sp/contents/column/20240226_chatgpt.html
特に、今月発表されたOpenAI o1-previewは理系科目で博士課程水準の推論能力を持つようです。
記事を書いている自分は修士2年なのですが、代わりに研究をお願いしたら、大量のアウトプットが期待できるのでは?と心躍っています。
しかしながら、上記のような汎用的LLMは、一般的な問題に対する推論能力は非常に優れている一方で、最新情報が反映されていない or 特定分野や組織固有の知識不足から、ハルシネーション(嘘をつく)が度々起きます。
これは、汎用的LLMが事前学習しているテキストデータの中に、確度の高い答えがないためです。
この問題点を解決するのが、RAG(Retrieval-augmented generation:検索拡張生成)です。
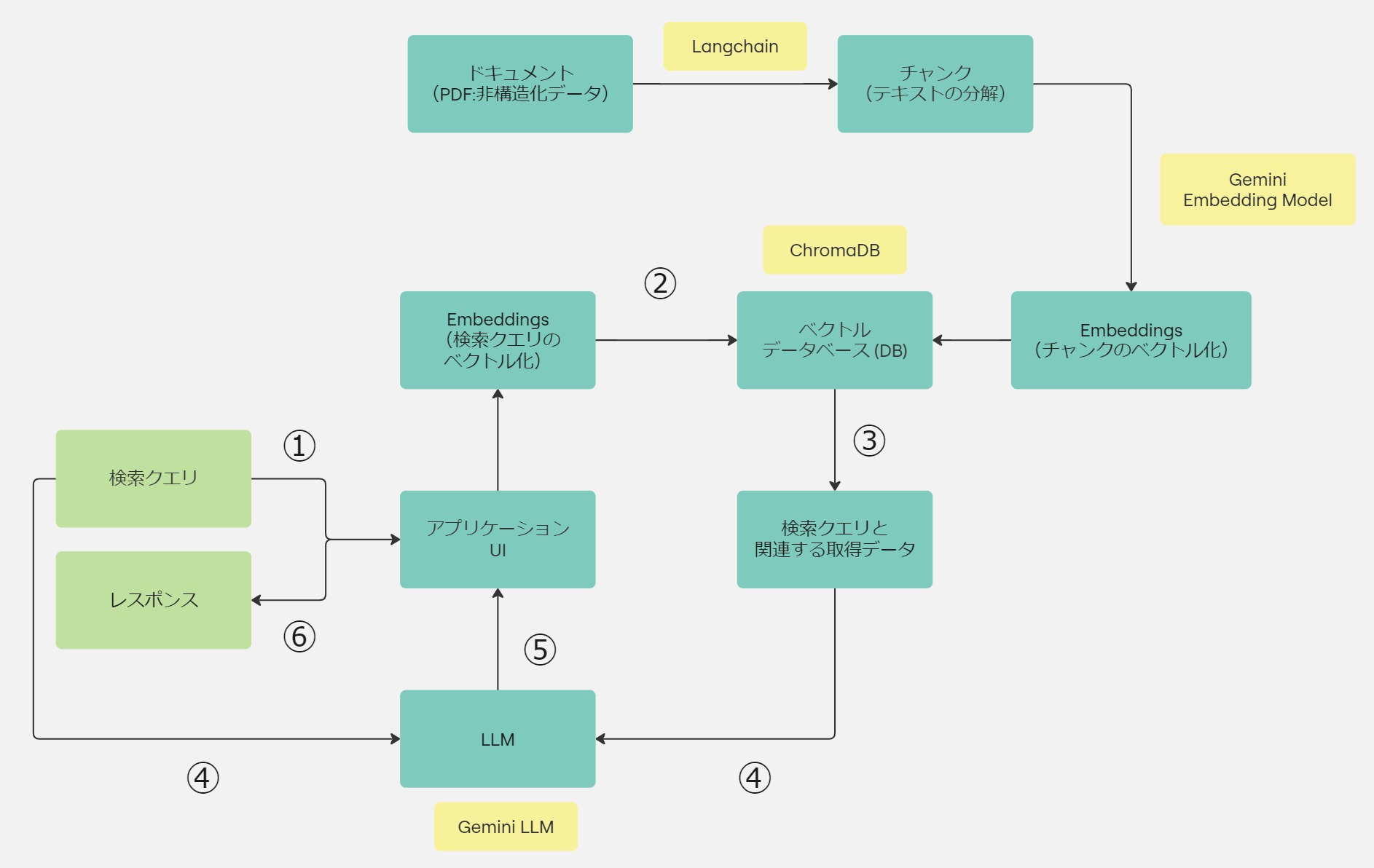
RAGの原理は、汎用的LLMに、外部記憶装置としてVectorDBを挟むことで、より確度の高い(検索クエリベクトルと結果ベクトルの類似度がより高い)結果を返すというものです。(下の図参照)
引用元:生成AIのビジネス活用で注目されるRAG(検索拡張生成)とは?(大和総研)
https://www.dir.co.jp/world/entry/solution/rag
RAGの原理
1. 検索フェーズ(LLMの知識を補完するために外部データを取得)
- ユーザーが質問を入力(図中➀)
- アプリケーションが外部データから関連文書を検索(図中➁)
- 関連性の高い文書を取得(図中➂
2. 生成フェーズ(検索結果を用いて回答を生成)
- ユーザーの質問と関連文書の情報をLLMに送信(図中➃)
- LLMが回答を生成(図中➄)
- アプリケーションがユーザーに解答を表示(図中➅)
最近では、QiitaやZennにおいて、RAGによる質問対応チャットボットの記事を数多く見受けられるようになりました。
しかし、70ページを超えるPDFを参照したRAGの構築はあるものの、検証が豊富に行われている記事がなかったため、今回実装&検証をしてみました。
本記事では、私が実装時に工夫したことや論文リサーチから得られた考察、豊富な検証を中心に、初学者でも理解できるように書いていこうと思います。
2. この記事の対象者
- Pythonを使って何かプロダクトを作ってみたいエンジニアの方
- RAGを使ったLLMシステムを試してみたいビジネス系の方
- 基本的に簡単な環境構築とコードしか扱わないため、ビジネス系の方でも実装できます。
3. 動作環境・使用するツールや言語・使用するPDF文書
- OSバージョン
- windows11
- 開発環境
- Google Colablatory
- ツール
- ChromaDB
- PyPDF
- OpenAI API
- gpt-4o-mini
- text-embedding-3-large
- 言語
- Python 3.10.12
- フレームワーク
- Langchain
- PDF文書
実際に企業特化LLMシステムを作る上で、50ページを超えるようなPDFを扱う場合を想定して、76ページのPDFを使用しています。- 化学薬品等取扱いの手引き(全76ページ)
4. LLMの選定基準
- Quality IndexとPriceのトレードオフ図からコスパが良さそうなのは、gpt-4o-miniなので、こちらを選択しました。
コストが気にならない方は、gpt-4oもしくはgemini-1.5proも良いかもしれません。
最近でたo1-previewは4oの10倍程度するので、毎日APIと叩くと1万くらい超えそうですね。。
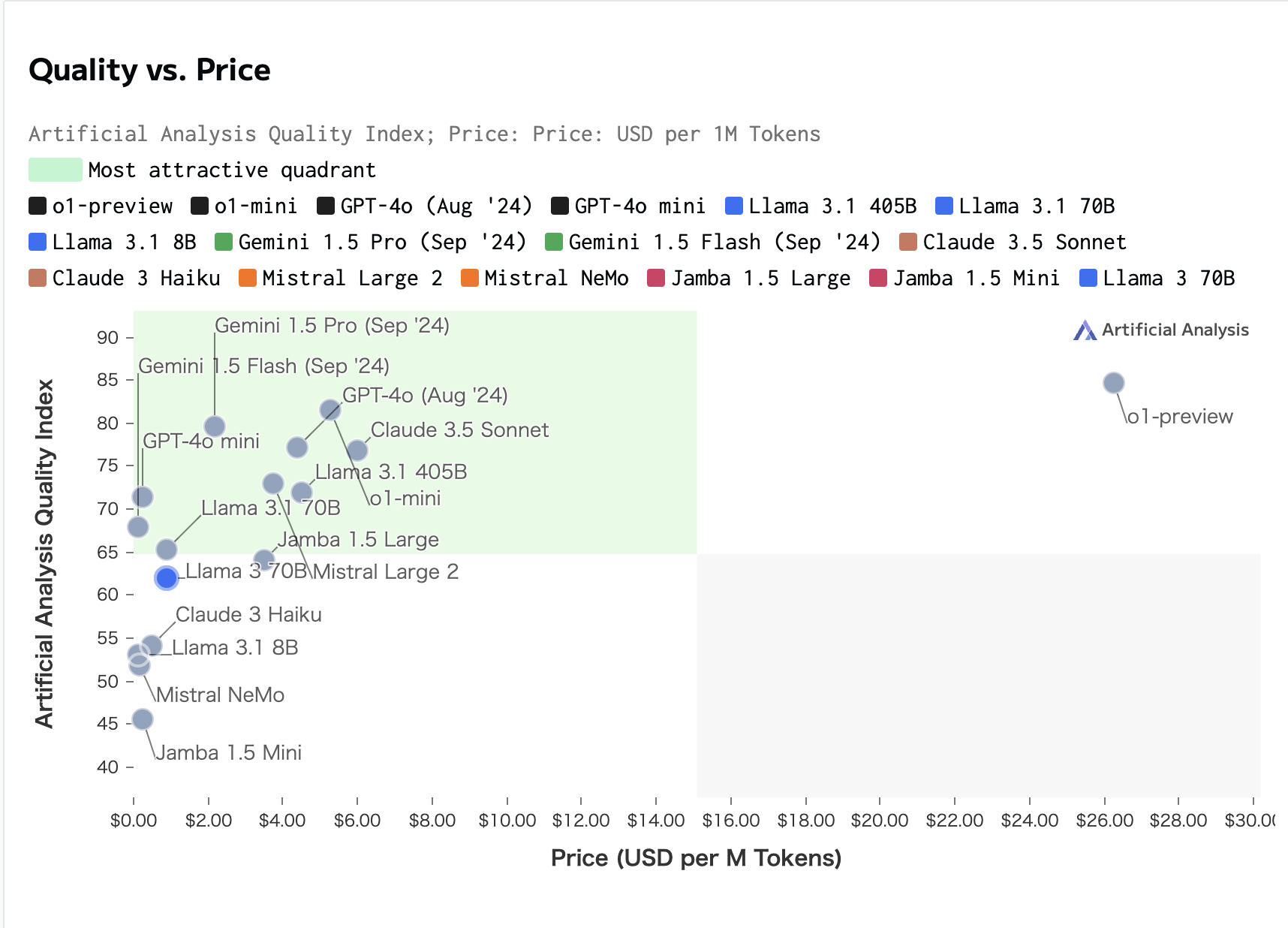
参考元 : Llama 3 Instruct 70B: Quality, Performance & Price Analysis
https://artificialanalysis.ai/models/llama-3-instruct-70b#pricing
5. 専門用語の解説
本題に入る前に、使用するフレームワークとベクトルデータベースを紹介します:
- Langchain
ChatGPTなどの大規模言語モデルの機能拡張を効率的に実装するためのライブラリです。RAGを実装する時は、基本的にLangchainのコンポーネントを多用して、コードを連結処理していきます。- LangChainの主要コンポーネント 7つ
- スキーマ (Schema)
データ構造や形式を定義し、コード全体での一貫性を確保する。 - モデル (Models)
大規模言語モデル(LLM)を扱うためのインターフェースを提供する。テキスト生成や質問応答などの機能を設定できる。 - プロンプトテンプレート (Prompt Templates)
LLMへの入力を構造化するためのテンプレートを提供する。ユーザー入力のフォーマットやLLMへの指示を定義できる。 - インデックス (Indexes)
大量のドキュメントコレクションを効率的に検索・取得するための仕組みを作れる。 - メモリ (Memory)
会話の履歴や状態を保持し、文脈を考慮した応答を可能にする。 - チェーン (Chains)
複数の処理ステップを連鎖させて、平行処理or逐次処理が選択可能なワークフローを構築できる。 - エージェント (Agents)
LLMとUIサービスを組み合わせ、アプリケーションを作れる。
- スキーマ (Schema)
引用元 : [LangChain Introduction]
https://python.langchain.com/docs/introduction/ - LangChainの主要コンポーネント 7つ
- ChromaDB
ベクトル埋め込みを格納し、大規模な言語モデル(LLM)アプリケーションを開発・構築するために設計されたオープンソースのベクトルデータベースです。
ちなみに、今回はベクトルデータベースとして、ChromaDBを用いています。理由としては、参考にできるテック記事が多く、完全無料で使用できるためです。Pineconeも参考にできる記事は多いですが、有料のため採用を見送りました。
6. 実装
それでは、RAGの具体的な実装手順に踏み込んでいきます。Google Colaboratoryを用いた環境構築から、実際のコーディングまで、順番に解説していきます。
6.0 必要なパッケージのインポートとOpen APIキーの設定
!pip install -U langchain-google-genai langchain langchain-community langchain_openai
!pip install openai chromadb tiktoken pypdf
!pip install pdfminer.six pi_heif
【パッケージの説明】
- google-auth-oauthlib: Google Driveマウント用
- pypdf: PDFファイルの処理を行う
- tiktoken: OpenAIのトークナイザー
- pdfminer.six: PDFテキスト抽出用
# OpenAI APIキーの設定
import os
os.environ["OPENAI_API_KEY"] = "sk-______________________"
6.1 必要なライブラリのインポート
まず、プログラムで使用する様々なツールや機能を持つライブラリをインポートします。
import os
import logging
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.vectorstores import Chroma
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.schema.runnable import RunnablePassthrough
from langchain.prompts import PromptTemplate
【ライブラリの説明】
PyPDFLoader: PDFファイルを読み込むRecursiveCharacterTextSplitter: 長いテキストを小さな部分に分割OpenAIEmbeddings: テキストを数値のベクトルに変換ChatOpenAI: チャットAIモデルを使用可にChroma: テキストデータを保存し、検索するためのベクトルデータベースConversationalRetrievalChain: 会話形式で情報を検索し回答を生成ConversationBufferMemory: 会話の履歴を保存RunnablePassthrough: 入力をそのまま出力PromptTemplate: LLMへの入力(プロンプト)を動的に生成
(補足) Google Driveをマウント(Google Colabで実行する場合)
from google.colab import drive
drive.mount('/content/drive')
Google Colabを使用している場合、このコードでGoogle Driveをマウント(接続)します。
これで、Google Drive上のファイルにアクセスできるようになります。
6.2 PDFの読み込みと前処理
PDFファイルを読み込み、テキストを適切なサイズに分割します。
loader = PyPDFLoader("/content/drive/MyDrive/化学薬品等取扱いの手引き.pdf")
pages = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=128)
split_docs = text_splitter.split_documents(pages)
【コードの説明】
PyPDFLoaderで指定したPDFファイルをloader変数に保存loader.load()を実行して、実際にPDFファイルの内容を読み込むRecursiveCharacterTextSplitterで長いテキストをチャンクに分割chunk_size=512は、各チャンクの最大サイズを512文字に設定chunk_overlap=128は、各チャンクが128文字分重なるように設定。文脈を保つために、チャンクの重ね合わせが必要になります。text_splitter.split_documents(pages)を使って、先ほど読み込んだPDFの内容を小さなチャンクに分割
**チャンクサイズとチャンクオーバーラップの決め方**
複数のサイトを参考にしましたが、どの記事も512チャンクサイズをお勧めしていました。オーバーラップは、数値が大きいほど会話履歴が保持させるので、50%にしてもよさそうです。
 |  |
|---|---|
・OpenAIのtext-embedding-ada-002モデルのチャンクサイズが異なるときのRecall@50値比較表。ベクトル検索のみで計算しており、512トークンのチャンクが最もパフォーマンスの値が高い。 | ・OpenAI社のtext-embedding-ada-002モデルで、25%の重複を含む512トークンのチャンクが最もパフォーマンスの値が高いため、これを採用する。 |
引用先:Azure AI Search: Outperforming vector search with hybrid retrieval and ranking capabilities
https://techcommunity.microsoft.com/t5/ai-azure-ai-services-blog/azure-ai-search-outperforming-vector-search-with-hybrid/ba-p/3929167
6.3 モデルとベクトルストアの初期化
LLMと埋め込みモデルを初期化し、ベクトルストアを作成します。
base_llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
llm = RunnablePassthrough() | base_llm
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
vectorstore = Chroma.from_documents(split_docs, embedding=embeddings, persist_directory=".")
vectorstore.persist()
【コードの説明】
ChatOpenAIクラスで初期化されたモデルを作ります。- modelは安い
gpt-4o-miniを使用します - モデルの出力を一意にするため
temperature=0にする
- modelは安い
RunnablePassthrough()は、入力をそのまま次の処理に渡します。|でパイプラインを作成し、入力をbase_llmにそのまま渡します。OpenAIEmbeddingクラスで初期化されたEmbeddingモデルを作ります。これはLLMモデルの作製と同じことをしています。from_documentsメソッドで、split_docs(事前に分割されたドキュメント)をエンベディングし、vectorstoreに保存します。- データの保存先に、すぐ確認できるように現在ディレクトリを指定します。
persist_directory="."
6.4 会話メモリとプロンプトの設定
会話履歴を保持するメモリと、LLMへの指示プロンプトを設定します。
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True,
output_key="answer"
)
template = """あなたは与えられた文書の内容に基づいて質問に答える専門家です。
質問に対して、文書の情報のみを使用して詳細かつ正確に回答してください。
文書に関連する情報がない場合は、「申し訳ありませんが、この文書にはその情報が含まれていません」と答えてください。
文脈情報:
{context}
質問: {question}
回答:"""
PROMPT = PromptTemplate(template=template, input_variables=["context", "question"])
【コードの解説】
ConversationBufferMemoryクラスを使用して会話履歴を管理する- 後で会話履歴にアクセスできるように、keyを指定する
memory_key="chat_history": return_messages=Trueで会話履歴をメッセージオブジェクトのリストとして返すように設定するoutput_key="answer"でAIの回答を保存するキーを指定する
- 後で会話履歴にアクセスできるように、keyを指定する
- AIに対する指示と質問のテンプレート
templateを定義する PromptTemplate: 動的にプロンプトを生成するためのテンプレートを作成する- input_variables=["context", "question"]: テンプレート内で使用される変数を指定
- ちなみに、今回は"context"を使用していないのですが、抜いて実行すると以下のようなエラーになりますので、ご注意ください。
ValidationError: 1 validation error for StuffDocumentsChain Value error, document_variable_name context was not found in llm_chain input_variables: ['question'] [type=value_error, input_value={'llm_chain': LLMChain(ve...None, 'callbacks': None}, input_type=dict]
- input_variables=["context", "question"]: テンプレート内で使用される変数を指定
LLMChainを作成する際には、プロンプトに "context" と "question" の両方が含まれている必要がある様です。
6.5 会話型検索チェーンの作成
ユーザーの質問に対して、関連情報を検索し回答を生成するチェーンを作成します。
qa = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=vectorstore.as_retriever(search_kwargs={"k": 3}),
memory=memory,
return_source_documents=True,
verbose=True,
combine_docs_chain_kwargs={"prompt": PROMPT},
chain_type="stuff",
return_generated_question=False,
output_key="answer"
)
【コードの解説】
vectorstore.as_retriever(search_kwargs={"k": 3})はベクトルストアから関連情報を検索するための検索エンジンの設定です。k=3は、質問に対する最も類似度が高いドキュメントを3つ取得するという意味です。memoryは会話の履歴を保持するための要素です。return_source_documents=Trueは、Trueにすると回答の生成に使用されたソースドキュメントを返します。今回は定性的に回答の精度を確かめるので、参照元を必ず確認する必要があります。verbose=TrueはLangChainのコンポーネントやチェーンの実行中に詳細な情報やデバッグの中身が見れます。参考元のようにこれだけ大体の実行状況の詳細が確認できます。参考元:LangChainでlangchain.verbose = Trueと書くと、それがChainのverbose属性に設定されるまで
https://nikkie-ftnext.hatenablog.com/entry/langchain-python-verbose-attribute-module-and-chain-instancecombine_docs_chain_kwargs={"prompt": PROMPT}は検索結果と質問を統合しています。chain_type="stuff"はすべての関連ドキュメントを一度にLLMに渡しています。return_generated_question=Falseはユーザーの元の質問に焦点を当てるために、LLM内部で生成された質問は返さない様にしています。output_key="answer"は生成された回答を格納するキーを指定しています。
6.6 システムの実行
実際に質問を投げかけ、システムからの回答を取得します。
query = "化学薬品等取扱主任者及び化学薬品等取扱責任者のうち、加速器研究施設区分の氏名を教えてください"
chat_history = []
# invoke メソッドを使用
result = qa.invoke({"question": query, "chat_history": chat_history})
print("\n最終回答:")
print(result["answer"])
【コードの解説】
queryでユーザーの質問を定義することができます。chat_history = []は空のリストを作成して、履歴を初期化しています。- `invoke'は同期実行を行うので、qa.invoke()で作成した一連の会話の流れが実行されます。
7 検索クエリに対する出力の検証
7.1 検索クエリ(query)の対象がよくある単語/文章であるとき
■ 検索クエリ
劇薬や毒物を扱うときは、どのように保存すればいいですか
■ 回答クエリ
劇薬や毒物を扱う際の保存方法は以下の通りです:
- 毒劇物は専用の金属製保管庫で、常時施錠して保管すること。
- 要管理物質は施錠可能な保管場所で保管すること。
- 保管庫は床等に固定すること。
- 保管庫には「医薬用外毒物」や「医薬用外劇物」の表示をすること。
- 薬品棚には転落防止用の措置を講じること。
- 保管庫に腐食、亀裂、破損等がないかを定期的に確認すること。
■ LLMが参考にした文脈情報
19 3-5.毒物・ 劇物・要管理物質 の取扱い
毒物及び劇物取締法により毒物又は劇物として指定されている化学物質 (p.58)については、以
下のように 適切な取扱 いをしてください。 また、特定毒物につい ては、特定毒物研究者の許可を受け
た者でなければ 使用できません。 要管理物質( p.59)は、毒劇物に準じた管理をお願いします。
##### ■ 容器について
・ 環境安全管理室発行のバーコードラベルを貼る
・ 飲食物用に使用される容器に移し替えてはならない
・ 別な容器に移し替えた場合はその容器にも「 医薬用外毒物 」(赤地に白字で )、「 医薬用外
劇物 」(白地に赤字 で)と表示する
##### ■ 保管について
・ 毒劇物は専用金属製保管庫で、常時施錠し保管する
・ 要管理物質は 施錠可能な保管場所での保管する
・ 保管庫は、床等に固定する
・ 保管庫に「 医薬用外毒物 」「 医薬用外劇物 」の表示をする
・ 薬品棚には転落防止用の措置を講じる
・ 保管庫に腐食・亀裂・破損等がないか定期的に確認する
■ PDF内の該当箇所

■ 結果と考察
完璧に回答できていました。検索クエリで、参照場所が保管であるところを保存と変えてみたり、要管理物質の取扱い等を省いてみたりと、実践的なクエリにしてみましたが、見事完璧に回答していました。
7.2 検索クエリ(query)の対象が特定の単語/文章であるとき
7.1の実験は、頻出するワードに対して検索をかけました。この7.2ではこの文章でおそらく1回しか出現しない"エネルギー分散型蛍光X線分析装置"について検索してみたいと思います。
■ 検索クエリ
エネルギー分散型蛍光X線分析装置について知ってることを教えてください
■ 回答クエリ
エネルギー分散型蛍光X線分析装置(島津製作所:EDX-8000)についての情報は以下の通りです。
- 用途: 固体・液体試料中の元素の定性及び半定量分析を行います。
- 検出可能元素: 6C(炭素)から92U(ウラン)までの元素を検出可能です。
- X線管球: Rh(ロジウム)ターゲットを使用し、4~50 kVの電圧と1~1000 μAの電流で動作します。
- 照射面積: 1 mm、3 mm、5 mm、10 mm φの照射面積を選択できます。
- 検出器: SDD(シリコンドリフト)検出器を使用しています。
- 検出下限: 数百 ppmから数%までの範囲で、測定元素や分析条件により異なります。
- 定量範囲: 数 %から上限は測定元素や分析条件により異なります。
この装置は、さまざまな試料に対して高精度な分析を提供するために設計されています。
■ LLMが参考にした文脈情報
・エネルギー分散型 蛍光X線分析装置 (島津製作所: EDX -8000)
用途:固体・液体試料中の元素の定性及び半定量分析
[仕様]
検出可能元素:6C~92U
X線管球: Rhターゲット( 4~50 kV、1~1000 A)
照射面積: 1,3,5,10 mm φ
検出器: SDD(シリコンドリフト)検出器
検出下限:数百 ppm~数%(測定元素、分析条件により異なる)
定量範囲:数 %~(測定元素、分析条件に より異なる)
■ PDF内の該当箇所
■ 結果と考察
- 元素番号が上付き文字から数字に変わっていました。
- 今回の元素記号の例では許容範囲な気がしますが、1020と10^20では全然意味が変わってくるので、このミスは良くないですね。
- 他のミスでは、1000μAのμが◻︎になっていました。
- 化学系では、電流値の単位を間違えると命取りになるので、これは非常に危険です。まだ◻︎であるため、PDF本文を参照しようとなりますが、これがm(ミリ)や◻︎が省略されていたら、感電死しかねません。
7.3 検索クエリ(query)の対象が表であるとき
■ 検索クエリ
化学薬品等取扱主任者及び化学薬品等取扱責任者のうち、加速器研究施設区分の氏名を教えてください
■ 回答クエリ
加速器研究施設区分の化学薬品等取扱責任者の氏名は以下の通りです。
- 加速器第一研究系: 久保田 親
- 加速器第三研究系: 丸塚 勝美
- 加速器第五研究系: 川村 真人
- 加速器第六研究系: 内山 隆司
- 応用超伝導加速器イノベーションセンター: 後藤 剛喜
上記の回答が合っているか確認するために、LLMが参考にした文脈情報が元のPDFと一致しているか確認します。
■ LLMが参考にした文脈情報
50 化学薬品等取扱主任者及び化学薬品等取扱責任者名簿
区分 氏名
加速器
研究施設 加速器第一研究系
久保田 親
加速器第二研究系
加速器第三研究系
丸塚 勝美
加速器第四研究系
加速器第五研究系 川村 真人
加速器第六研究系 内山 隆司
応用超伝導加速器 イノベーション センター 後藤 剛喜
■ PDF内の該当箇所

■ 結果と考察
加速器第五.六研究系と応用超電導加速器イノベーションセンターの3人は正解しており、加速器第二.四研究系は間違えていました。
回答が間違ってしまった理由は以下だと考えられます。
- LLMが参考した文脈情報の構造化ができていない
- PDFの時には縦横の直線で構造化されていたが、PDFからPyPDFLoaderで直接テキスト分割したため、構造が壊れたと推定される。
■ 今後の課題
表形式データは、構造を維持するために、各セルの区切りには"|"を用いて配置と関係性を考慮する必要があります。
しかしながら、PyPDFLoder自体にテキスト抽出時の構造化命令を直接組み込むことはできません。これを改善するには、PyPDFLoder以外で、パーサーのみで表構造を取得可能なライブラリを探す or OCR→LLMで構造化しなおす or LLM単体で構造化しながら読み込むといった方法を新たに試す必要があります。
7.4 検索クエリ(query)の対象が表であるとき
再度、異なる表の検証を行います。
■ 検索クエリ
第一種酸化性固体の推定数量は?
■ 回答クエリ
回答:
申し訳ありませんが、この文書にはその情報が含まれていません
■ LLMが参考にした文脈情報
8 1-7のいずれかを含有するもの 第一種可燃性固体
第二種可燃性固体 100 kg
500 kg
9 引火性固体 固形アルコール 1,000 kg
第三類 自然発火性
物質
及び
禁水性物質 1 カリウム
2 ナトリウム
3 アルキルアルミニウム
4 アルキルリチウム 10 kg
5 黄りん 20 kg
6 アルカリ金属( カリウム 及びナ
トリウム を除く。 )及びアルカリ
土類金属
7 有機金属化合物( アルキルアル
ミニウム 及びアルキルリチウム
を除く。 )
8 金属の水素化物
9 金属のりん化物
10 カルシウム 又はアルミニウム の
炭化物
11 その他、政令で定めるもの
12 1-11のいずれかを含有するもの 第一種自然発火性
物質、禁水性物質
第二種自然発火性
物質、禁水性物質
第三種自然発火性
物質、禁水性物質 10 kg
50 kg
300 kg
■ PDF内の該当箇所

■ 結果と考察
回答不可でした。そもそも参照している場所が違う&参照しているデータ構造が崩壊しているので、やむをえない結果だと思います。
やはり、7.3と同様で、OCR+LLMもしくはLLMのみで構造化することが必要であると思われます。
まとめ
今回はRAGの原理から実際にGoogle Colabratoryで構築と検証を行いました。
結果としては、検索クエリの対象が文章である場合回答でき、検索クエリの対象が表になると回答できないor回答ミスが起きることがわかりました。
今回使用したPDFは化学薬品系の内容なのですが、重要なデータである数値や人の名前は基本的に表として構造化されているので、今後はこの表を綺麗に維持したままLLMで読めるRAGシステムを構築できるように試行錯誤していきたいと思います。
今回はPDFパーサーのみ使用して、テキスト化しました。
次回は、OCR(Google Vision API)+LLM を用いる2ステップの手法、さらには、LLMのみで画像から直接情報抽出するEnd-to-Endな手法、この2つを比較して、最も精度の高いLLMシステムを検討していきたいと思います!
読んでいただきありがとうございました。
この記事の続編はこちら!
宣伝
弊社ではデータ基盤策定からLLMまで、お客様にあったプロセスでの提案とご支援が可能です、お気軽にお問合せください。
また、中途採用やインターンの応募もお待ちしています!