
はじめに
- AirbyteのOSSについて採用する企業さんも増えている印象です
- 日常の定期的に転送するデータより、少し大きめのデータで勝手を知っておきたい
- ベースラインとしてTROCCOでの転送時間も取得し、その使い勝手や転送速度も比較しておきたいということで検証してみました
大切なおことわり
- 正確な非機能検証というスタンスではありません
- マシンのスペックや環境等もそれぞれが違うので、あくまで同じデータ(転送元データ)を各サービスで転送したときにそれぞれの良さがどの辺にあるかを理解できればというスタンスです
転送元
MySQL
- AWSで構築
- Aurora MySQL8.0(リージョン:バージニア北部、サイズ:db.r6g.xlarge)
- 構築手順は割愛(VPCの設定などは今回加味せず、パブリックアクセスからの対応)
データの準備
- kaggle datasetにあるConsumer Complaint Databaseを利用
- データサイズとしては、圧縮展開後でローカル計測では2.87GB、行数としては8,341,600行(約800万行ほど)
- データの中身は詳しくみていないが、文字多めの一部dateやbooleanっぽい
MySQLのデータロード
AWS上でAurora起動後、データのロードまで実施(下記はコマンドの実行イメージ)
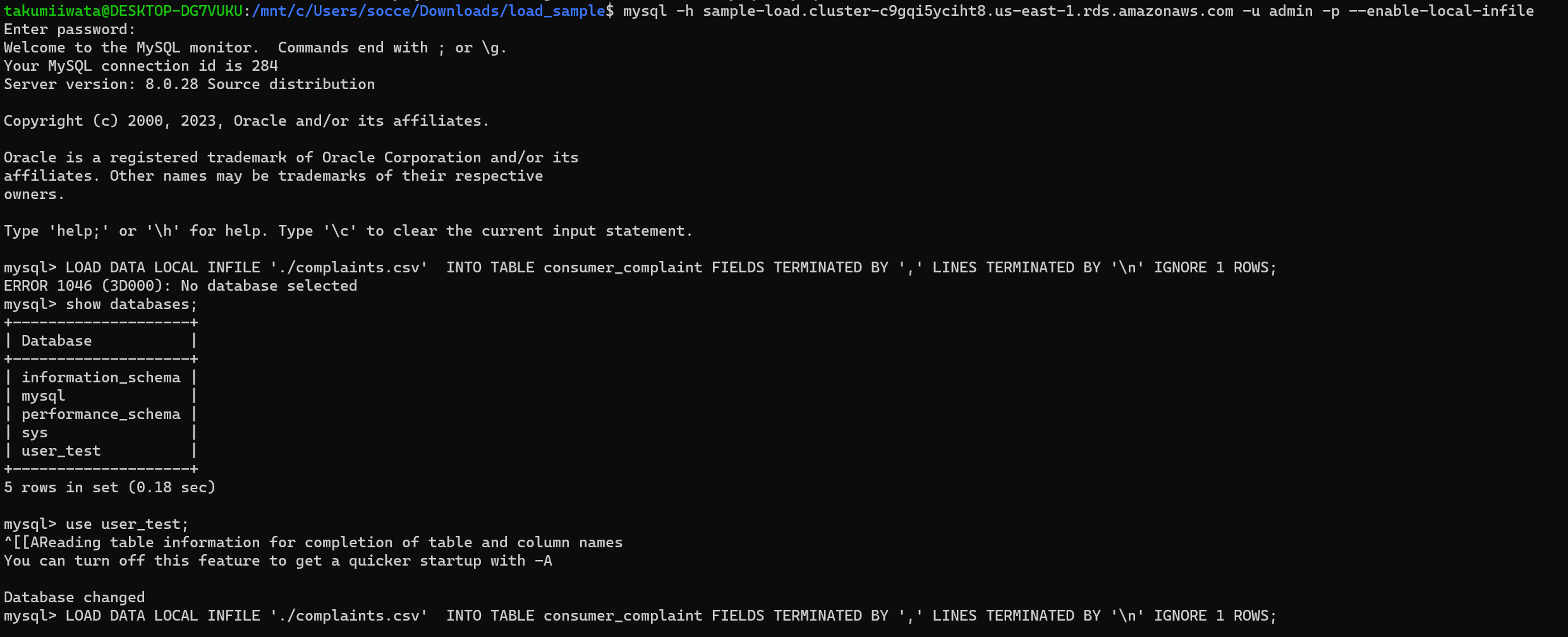
MySQLへのアクセス:ホスト名やデフォルトユーザーは適切に変える
mysql -h sample-load.cluster-c9gqi5yciht8.us-east-1.rds.amazonaws.com -u admin -p --enable-local-infile
転送元テーブルの作成
create table consumer_complaint \
(
date_received date , \
product varchar(100) , \
sub_product varchar(100) , \
issue varchar(1000) , \
sub_issue varchar(1000) , \
consumer_complaint_narrative varchar(100) , \
company_public_response varchar(100) , \
company varchar(100) , \
state varchar(10) , \
zip_code varchar(10) , \
tags varchar(100) , \
consumer_consent_provided varchar(100) , \
submitted_via varchar(100) , \
date_sent_to_company date , \
company_response_to_consumer varchar(100) , \
timely_response varchar(10) , \
consumer_disputed varchar(100) , \
complaint_id varchar(10) \
);
LOAD DATA IN FILE:解凍したファイルの場所を適切に指定
LOAD DATA LOCAL INFILE './complaints.csv'
INTO TABLE consumer_complaint
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
IGNORE 1 ROWS
;
実行するローカルマシンにもよるとは思いますが、テーブルへの取り込みまでに44分ほどかかりました。
時間を短縮したい場合は元ファイルのデータ件数をサマってから実行するほうがよさそうです。
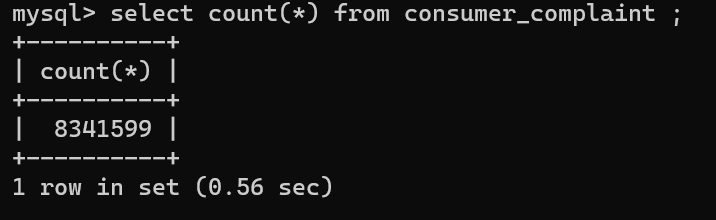
MySQLの取り込み件数としては 8,341,599 件と少しSKIPされているかもしれません。
転送先
BigQuery
- データセットのリージョンは東京に設定し、AirbyteとTROCCOで新規のテーブルを作成
転送に利用するサービス
Airbyte
- OSS版を使用
- 環境はローカルへの展開でも良かったのですが、Google Cloud側に展開してみました
- Compute Engineを利用
- 既に運用されている企業さんのBlogを見る限り、本格的に回すのであればGKEが良しだとは思いますが検証なので
- リージョンは東京、マシン構成としては汎用のE2(コア4、メモリ8)、バランス永続ディスクの100GB
- Compute Engineを利用
Airbyteの準備
- Google Cloud 上で展開する場合、基本公式のDocに沿って作業をするだけです
- https://docs.airbyte.com/deploying-airbyte/on-gcp-compute-engine
- 他のクラウド環境でも公式Docの通り、Docker上に展開するだけでほぼOKだと思います(ちなみにDebiantベースの稼働確認とありますが、ubuntuでも問題なく稼働します)
TROCCO
- TROCCOのサービス環境はAWS(EKS)である想定(下記ページから読み取り)
結果
同時に転送サービスを起動するのではなく、順番に起動しセッション数やIOPSは空けた状態で確認
実行時間(分) | 備考 | |
|---|---|---|
Airbyte | 13:08 | MySQL側にあり得ない日付が入っていたのでオミットし、再実行 |
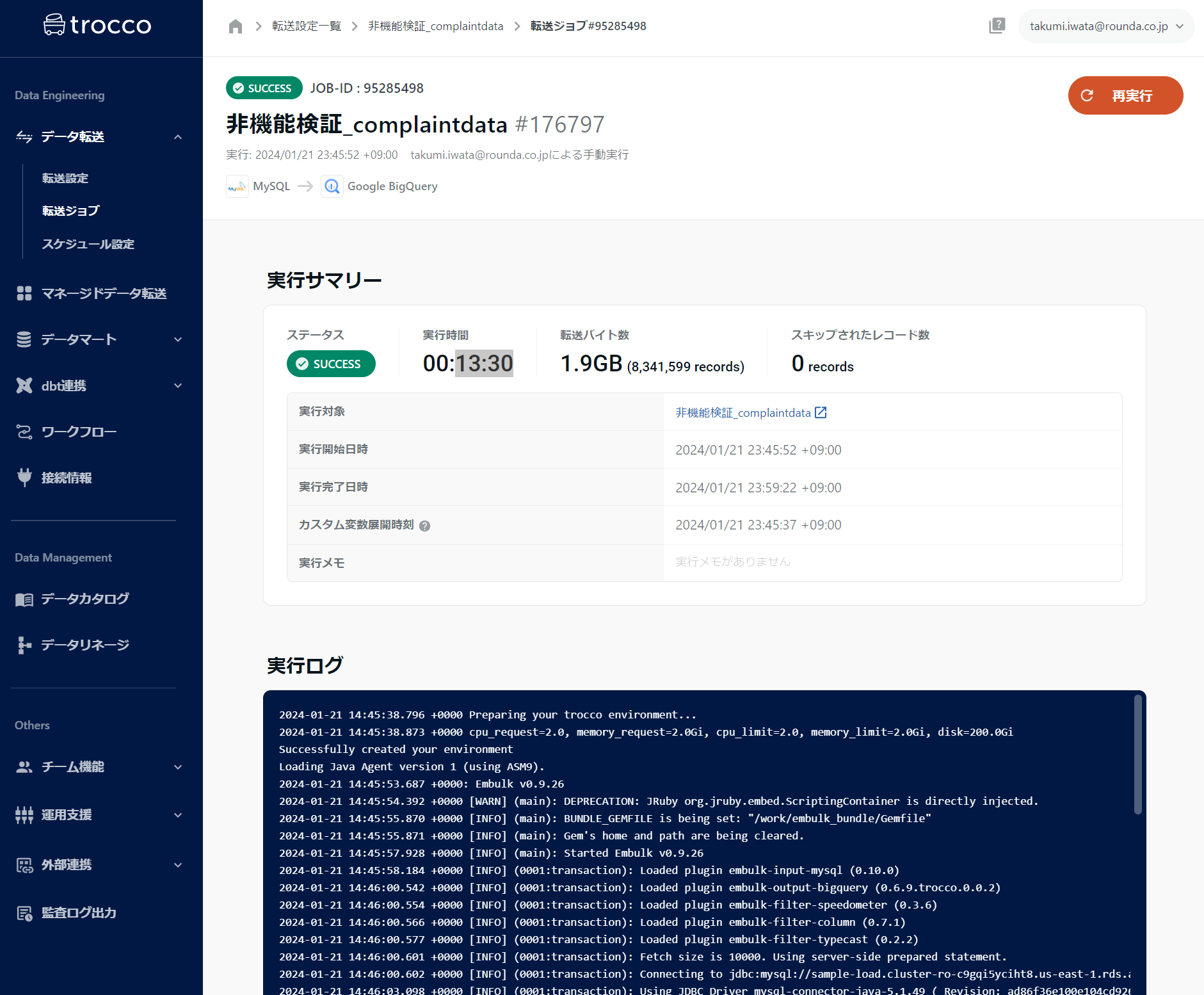
TROCCO | 13:30 | 何事もなく一発で転送完了 |
TROCCCOのリザルト画面
- ワーカーへのリソース割り当てはLogの2行目にある内容
cpu_request=2.0, memory_request=2.0Gi, cpu_limit=2.0, memory_limit=2.0Gi, disk=200.0Gi
Airbyteのリザルト画面
- ワーカーへのリソース割り当てはよく調べていないが、おそらく小さなものではないか?という印象
- Airbyteの方がデータ転送量が大きいのは、思ったより日付データが汚れており一括で修正をかけたため、ダミー内容のデータ量が増えています(件数だけ同じ)

考察とか感想
だいたい同じような時間で処理が終わりました。MySQLへのLoad Data in FIleで44分かかったことを考えると体感早いなという印象です
基本的に両者ポチポチで転送設定が可能です。
処理完了に至るまでの違いとしては、Airbyteではデータのオミットが必要となりました。
イメージとしては下記のようなあり得ない日付がMySQLでは設定が可能です。
AIrbyteの場合はサービス内でJavaでの変換時に関数エラーとなる形でデータのオミットが必要であり
TROCCOでは何事もなく転送が完了しました。ちなみにTROCCOで転送された結果は "1985-01-31" となっていました。

あくまでミクロの話なので他コネクタレベルで探れば、状況として両者が入れ子になるシーンもあるかと思います。 ただ、とりあえずすんなりデータを転送してほしいシーンと、早い段階でデータの異常に気付いておきたいシーンはあるかと思うので そのような観点から比較してみるのも面白いとは思いました。
サービスのUI/UXは比較すると時間がかかるので別の機会に行うとして、今回特に見たかったAIrbyte(OSS)の良さだけをざっくり書くと
- OSSでも起動がかなり手軽に行える
- 単一のインスタンス起動でも数GB以上のデータ転送(バッチ転送でのジョブ直列転送がメイン)等も問題なく利用できる
- 転送を行うにあたり、カラム単位で細かい設定を入れるというより転送元と転送先の同期(Sync)の用途がメインの印象で、一括で転送設定が出来上がる
- MySQL等であれば、CDCなど差分転送に容易に利用でき、転送先のテーブルに関してはメタ要素のカラム付でパーティションやクラスタキーの設定などもあり
- コネクタを自分で構築できるのは強み
といった印象です。TROCCOと同様にキャッチアップコストをかけずに十分始められるサービスかと思います。
もっと一つのサービスに焦点を当てた記事もどんどん書いていきますので、良ければ次回もお楽しみに!
宣伝
弊社ではデータ基盤策定からLLMまで、お客様にあったプロセスでの提案とご支援が可能です、お気軽にお問合せください。
また、中途採用やインターンの応募もお待ちしています!


